Time-Series Classificatie doormiddel van shapelets (2)
Zoals in deel 1 van deze drieluik te lezen hebben we een uiteenzetting gemaakt hoe complexe timeseries te vertalen zijn naar ‘shapelets’. Een mogelijk probleem wat geschikt zou zijn voor deze aanpak is het verbeteren van de uitleesbetrouwbaarheid van IoT apparaten.
IoT apparaten hebben ervoor gezorgd dat er een snelle toename is in beschikbaarheid van meetdata. Echter het gebruiken van deze meetdata blijft op dit moment in veel gebieden achter omdat het te kostbaar is om alles daadwerkelijk in te lezen. De oplossing die hier vooral voor gebruikt wordt is op een gegeven interval een meetwaarde uit de database op te halen. Met de dataset van dit interval wordt een classificatiemodel getraind. Dit classificatiemodel is in feite een generalisatie van het probleem. Hierdoor is het in staat om op hoofdlijnen afwijkingen te vinden, maar bijbehorende kleine details weg te laten. Dit resulteert dat het model minder goed in staat is om een juiste extrapolatie van minder vaak voorkomende covarianties in de probleemstelling te vinden. Door gebruik te maken van shapelets zou dit een flinke verbetering moeten opleveren.
Casus: Security Operation Center (SoC) wil beter inzicht krijgen of ze worden aangevallen.
Probleem:
Aanvallen van buitenaf nemen elke dag toe. Bijvoorbeeld Wannacry ransomware is een van de grootste cyber-attacks met globale impact op dit moment. De digitalisatie van onze samenleving heeft ervoor gezorgd dat bedrijven hier steeds meer alert op moeten worden. Gegeven dit feit heeft SoC ervoor gekozen om binnen hun infrastructuur meer meetpunten aan te leggen om hierop te kunnen toetsen. Dit heeft er echter voor gezorgd dat de logs die ze bij moeten houden ook exponentieel gegroeid zijn. Tot nu toe hebben ze ervoor gekozen om de logs die ze binnen krijgen te normaliseren doormiddel van wat hen als risicovol beschouwen. Hierna hebben ze gezocht naar gelijkende afwijkingen over een gegeven interval (correlatie). Toch blijken vooral nieuwe aanvallen compleet anders te zijn dan wat de oplossing als een mogelijke inbraak beschouwd. Dit heeft ermee te maken dat de oplossing alleen kennis over verwachtte correlaties heeft die in het verleden zijn opgetreden over minimaal een gegeven interval met een gewogen bereik. Hierdoor kan het maar lastig omgaan met het toewijzen van een nieuw event aan de mogelijke classificatie.
Oplossing:
Genereren van kandidaten
Om dit probleem op te lossen zal er gebruik gemaakt moeten worden van het genereren van mogelijke staten van de eventslog. Deze staten noemen we kandidaten.
De mogelijk aantal kandidaat shapelets voor een gegeven dataset T is dan:
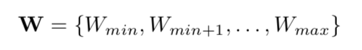
 Waarbij de maximale set W komend van lengte timeseries M en kandidaat oplossingen L:
Waarbij de maximale set W komend van lengte timeseries M en kandidaat oplossingen L:
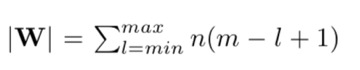

De afstand (verschil) tussen shapelets wordt berekend door gebruik te maken van het kwadraat van euclidische afstand tussen twee gekozen tijdsmomenten S en R, waar beiden zijn van lengte L:
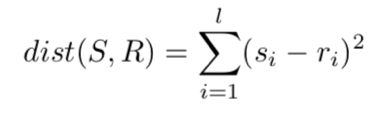
 De afstand tussen de timeseries Ti en de tijdsmomenten S van lengte L is de minimale afstand tussen S en alle genormaliseerde lengte L tijdsmomenten van Ti.
De afstand tussen de timeseries Ti en de tijdsmomenten S van lengte L is de minimale afstand tussen S en alle genormaliseerde lengte L tijdsmomenten van Ti.
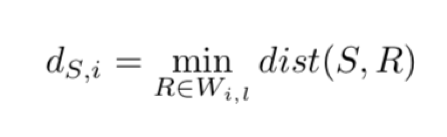
 We berekenen de afstand tussen kandidaat S en alle series in T voor het genereren van een lijst van N-afstand,
We berekenen de afstand tussen kandidaat S en alle series in T voor het genereren van een lijst van N-afstand,
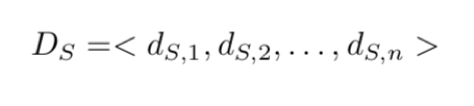
 Bepalen van kwaliteit van shapelet
Bepalen van kwaliteit van shapelet
De kwaliteit van de shapelet is gebaseerd op hoe goed de klassen C verschillen bij een set met de afstand Ds. De beste manier om dit te bepalen is gebruik te maken van informatie verbetering. Informatie verbetering betekent dat bij elke split (sp) die wordt gedaan door het algoritme er gekeken wordt hoe onderscheidend deze split is binnen de timeseries.
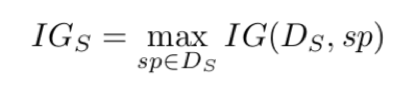
Predictie
Indien het model ingetraind is en de optimale waarde heeft gevonden kan er redelijk makkelijk een predictie worden gedaan in hoeverre een bepaald interval timeserie overeenkomt met een gegeven shapelet. Hierbij kan er ook gekozen worden om een top N shapelets terug te geven. In het algemeen werkt het als volgt:

In deze blog hopen wij abstract meer inzicht te hebben verschaft in het gebruik van een shapelet classifier voor timeseries data. In onze derde en laatste blog in deze reeks zullen we ingaan op strategieën om de intraintijd van een shapelet classifier te verbeteren.
Meer artikelen

Imad el Fetouh, ambitieuze junior consultant die houdt van een uitdaging
Imad (23) maakt deel uit van een nieuwe garde junior consultants die na de zomer bij Open Circle Solutions startte. Net als Yaris is hij ‘fresh out of school’ en staat hij te trappelen om zijn loopbaan te verkennen. Zijn eerste stappen zet hij bij OCS.Dat is voor Imad...

OCS Academy in het teken van Scrum Awareness
De OCS Academy is een repeterend jaarprogramma gericht op de startende consultant. Die leert van een ervaren rot in het vak, die zijn kennis en ervaring op een specifiek onderwerp met zijn jongere collega’s deelt. Dit keer stond de OCS Academy in het teken van Scrum...

OCS Family Event in de Efteling
Bij Open Circle Solutions weten we dat er meer is dan alleen werk... Nee, serieus: onderling contact buiten werkuren ís erg belangrijk voor onze cultuur en samenwerking. Niet voor niets organiseren we meerdere events per jaar waar onze medewerkers elkaar treffen in...
Nieuwsbrief
Meld je nu aan voor Open Circle Stories en krijg een verzameling artikelen, tips, nieuws en verdiepingen in je mailbox.
vragen?
Algemeen: +31 40 304 1330
Afdeling verkoop: +31 40 304 1572
info@opencirclesolutions.nl
Kantoor adres:
Daalakkersweg 16
Kantoor 6
5641 JA Eindhoven

