Natural Language Processing: slimmer omgaan met taal en tekst
Dat Open Circle Solutions beeldherkenning gebruikt voor bepaalde toepassingen, is bekend. Wat minder bekend is, is dat we ook actief zijn op het gebied van Natural Language Processing: een deelgebied binnen de Data Science dat zich bezighoudt met de interactie tussen computer en menselijke taal. Dit is de technologie achter online vertalers, virtuele assistenten en spraakherkenning. Wat beide specialisaties gemeen hebben, is dat ze zijn gebaseerd op deep learning en neurale netwerken. In deze serie artikelen duiken we dieper in deze technologieën, laten we je zien hoe wij er gebruik van maken én wat jij er eraan kunt hebben als organisatie. In dit blog leggen we je uit wat Natural Language Processing is en en nemen we een eerste stap in hoe neurale netwerken hierin worden gebruikt.
Door: Sander Kerdijk
Natural Language Processing
Als consultant in de data science kom ik veel nieuwe ideeën en methodieken in mijn vakgebied tegen. Data science is een divers vakgebied, samengesteld uit veel disciplines. Een voorbeeld is de natuurlijke taalverwerking of Natural Language Processing (NLP). NLP combineert inzichten uit de taalkunde, wiskunde en computerwetenschappen om computers te helpen de natuurlijke menselijke taal te begrijpen en gebruiken. Daarvoor onderzoekt het de relatie tussen data, betekenis en het begrijpen van de omvangrijke verzameling van tekstdata in onze wereld. Natural Language Processing wordt gebruikt in spamfilters, predicatieve tekst, virtuele assistenten (zoals Siri en Cortana), zoekmachines, tekstbegrip (zoals de grammatica-check in Word) en vertalers zoals Google Translate.
NLP is een moeilijk en weerbarstig vakgebied. Dat komt omdat de menselijke taal erg complex is: ongeorganiseerd, dubbelzinnig en onderhevig aan voortdurende verandering. De betekenis van een woord kan verschillen naar gelang de situatie, bedoeling, persoon die het uitspreekt of een hele reeks aan andere kenmerken. Dit maakt het lastig om woorden, begrippen en woordcombinaties eenduidig te vertalen naar een oplossing die door een computer kan worden begrepen. Het vakgebied zoekt daarom continu naar nieuwe technieken om de computer te ondersteunen de menselijke taal en communicatie beter te doorgronden. Eén van de nieuwste technieken die heeft bijgedragen om deze vertaalslag te versnellen, zijn zogenaamde ‘transformers’. In dit blog leg ik je uit wat een ‘transformer’ is en hoe deze is ontstaan.
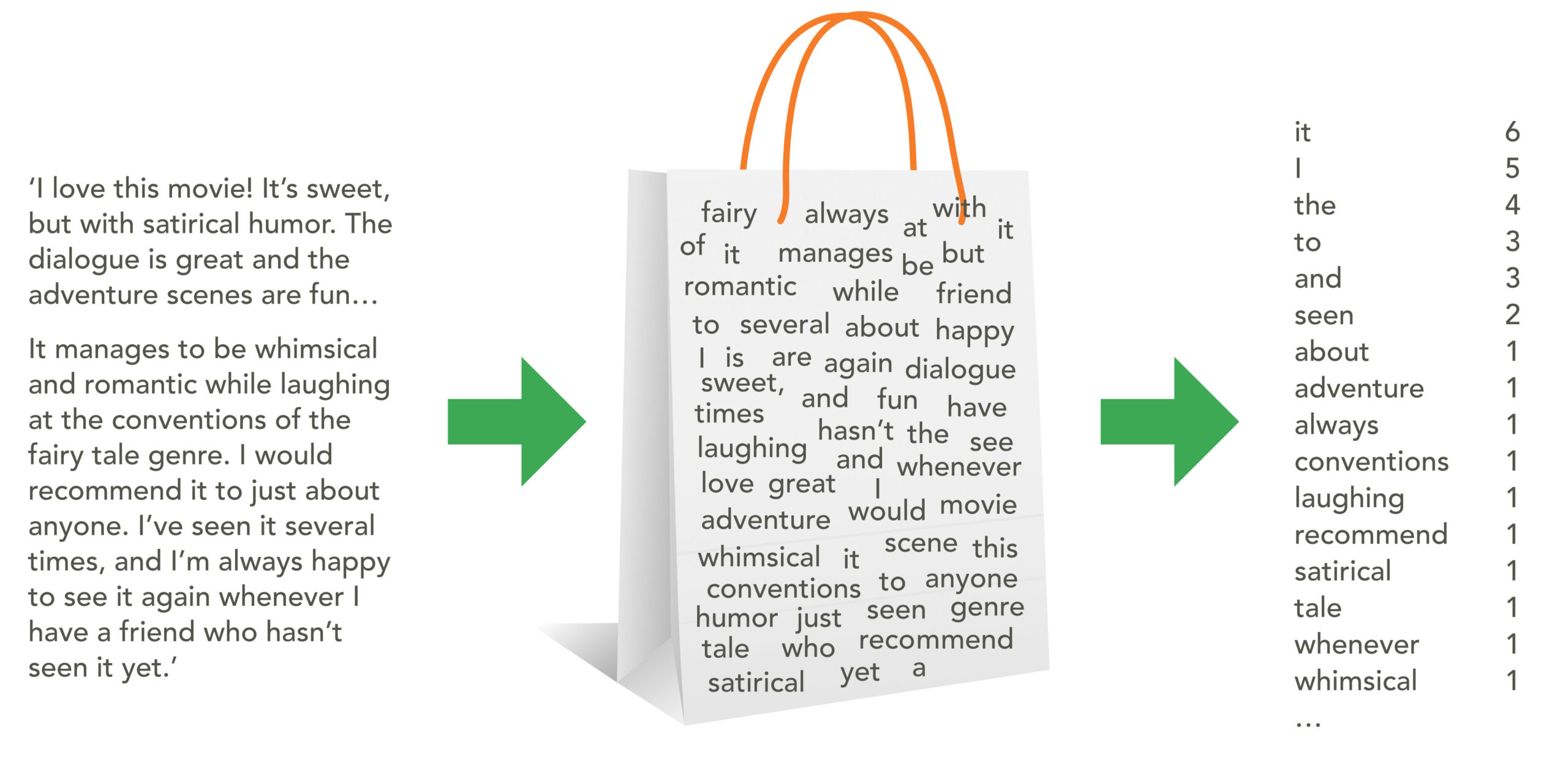
De simpelste vergelijking van een NLP-model is die met een zak vol woorden: ‘Bag of Words’, waarbij wordt geteld hoe vaak een woord voorkomt in een stuk tekst.
Hoe werkt Natural Language Processing?
Natural Language Processing gebruikt algoritmes om de spelregels van de taal te herkennen en formaliseren. Daarbij wordt gekeken naar de syntax (volgorde) en semantiek (betekenis). Door een computer grote hoeveelheden tekst voor te schotelen en te helpen bij deze analyse, wordt deze steeds accurater bij het interpreteren van de tekst. De computer doet dat niet zelf, maar wordt getraind.
We gebruiken daarbij deep learning en neurale netwerken. Neurale netwerken zijn een vorm van kunstmatige intelligentie waarbij een computer leert van grote hoeveelheden data. Door het tonen van heel veel voorbeelden, goede én foute, leert het de regels die wij gebruiken in onze taal. De computer is dan in staat een relatie te leggen tussen verschillende losse elementen en vormt zo netwerkpaden. Deze netwerkpaden worden, net als de neurale netwerken in het menselijk brein, sterker en korter naarmate de computer zich ontwikkelt en beter in staat is associaties te leggen tussen de geleverde input en de gewenste output.
Uiteindelijk, als er voldoende voorbeelden zijn, is de computer in staat een structuur te vormen die zonder hulp input kan verwerken en bruikbare output kan produceren op basis van de relaties die hij tijdens zijn trainingsfase heeft gevormd.
Je ziet hoe deze technologie effectief ingezet kan worden om een computer te helpen menselijke taal beter te begrijpen en na te bootsen. Geef het neurale netwerk gewoon een paar klassieke teksten van Shakespeare en het zal in mum van tijd het menselijke proza doorgronden, toch? Helaas is dit niet het geval, en hoewel neurale netwerken een grote stap in de goede richting zijn, zijn ze alleen een stukje van de puzzel die menselijke taal is.
Woorden bestaan nu eenmaal niet onafhankelijk van elkaar. Een reeks woorden krijgt een nieuwe betekenis door andere woorden toe te voegen of weg te halen, of als de context waarin ze wordt uitgesproken, verandert. Goed begrijpen van onze warrige tekst is nu eenmaal heel complex. Hoe slim ze ook zijn en hoe goed ze ook getraind worden, neurale netwerken hebben nog steeds moeite om relaties tussen opeenvolgende woorden en zinsdelen te begrijpen, zelfs als ze over voldoende trainingsgegevens beschikken. Dat zal voorlopig nog wel een tijd zo blijven.
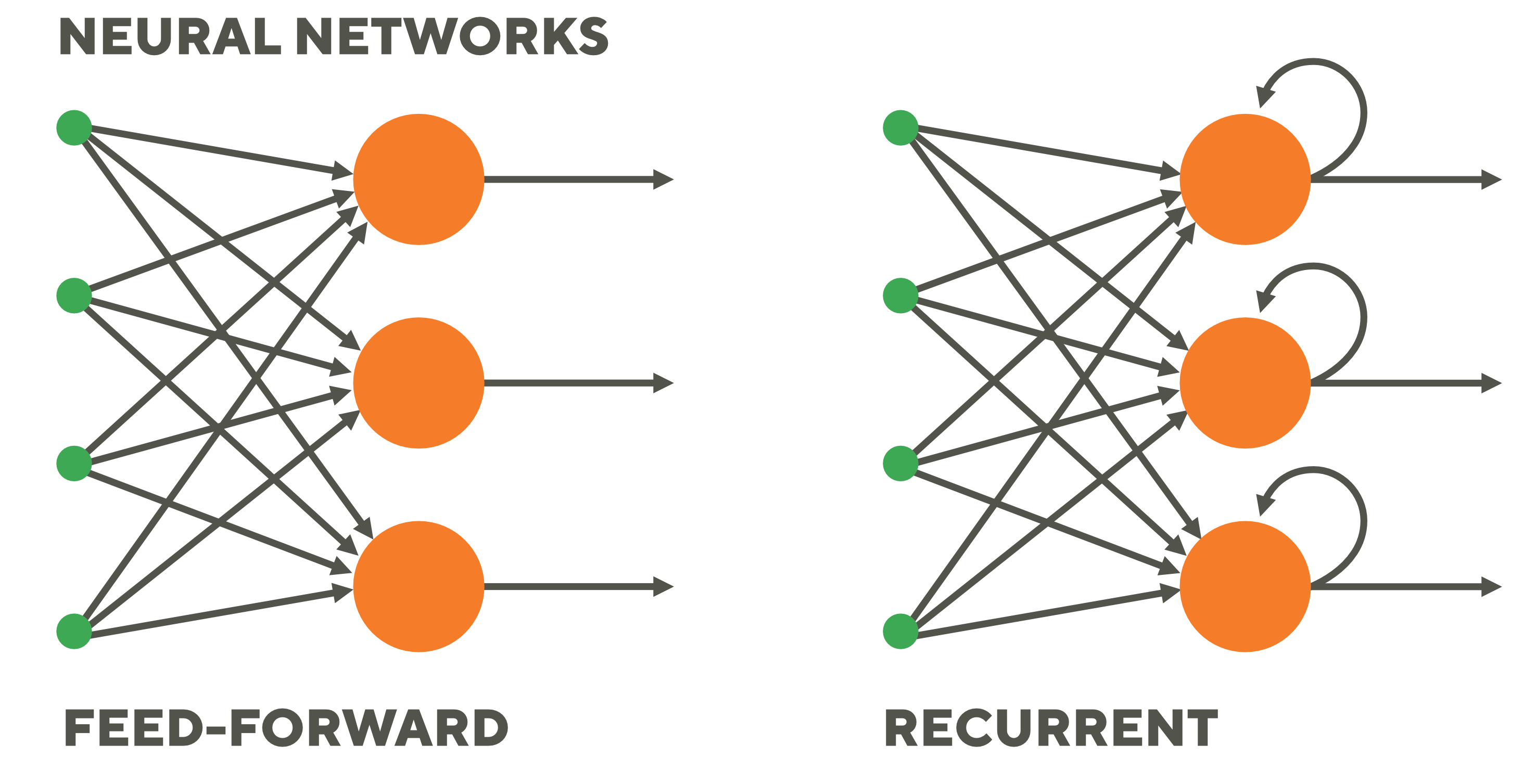
Feedforward neurale netwerken geven de gegevens door van invoer naar uitvoer, terwijl terugkerende netwerken een feedbacklus hebben waar gegevens op een bepaald moment kunnen worden teruggevoerd naar de invoer voordat ze weer worden doorgestuurd voor verdere verwerking en uiteindelijke uitvoer.
Eén van de veelbelovende toepassingen van Natural Language Processing is het geautomatiseerd optimaliseren van marketingteksten. Denk aan e-mails, digitale nieuwsbrieven, calls to action op je website en posts op social media. NLP gebruikt alle kennis die je hebt over je klanten en prospects om je boodschappen te optimaliseren. Uit onderzoek blijkt dat dit groot voordeel oplevert: 10% – 40% hogere open en click through rates zijn heel normaal. Geen wonder dat vrijwel alle grotere online aanbieders hier inmiddels gebruik van maken. Open Circle Solutions maakt deze technologie ook voor jouw organisatie toegankelijk.
RNN’s Recurrent Neurale Netwerken en het probleem van ‘Sequence Learning’
Het antwoord op deze valkuil van het neurale netwerk is het creëren van het recurrent neural network (RNN). Uitgangspunt is, dat taal kan niet worden gezien als een reeks afzonderlijke woorden die in een volgorde zijn gerangschikt en geïsoleerd, stuk voor stuk worden geïnterpreteerd. Taal bestaat uit reeksen van interrelationele begrippen die in een zin, alinea of compleet artikel voortdurend met elkaar in wisselwerking staan. Pas in hun samenhang kun je ze begrijpen.
Om de betekenis van een woord correct te interpreteren, is het daarom nodig om die te koppelen aan de betekenis van woorden daaraan voorafgaand of daaropvolgend. Een RNN kan dat. Die loopt door de gegevens en koppelt relaties tussen datapunten in een rekenkundig complexer en daardoor duurder proces. In plaats van te proberen een film te begrijpen door steeds losse fragmentjes van een seconde aan elkaar te plakken, kijkt een RNN naar alle fragmenten en maakt een verbinding tussen deze frames om te begrijpen wat er daadwerkelijk gebeurt.
Een RNN kan worden gezien als een reeks neurale netwerken, elk aan elkaar vastgeketend op basis van wat eraan voorafging. ‘Recurrent’ (terugkerend) slaat op het vermogen van de RNN om, eenmaal aangekomen bij een woord, terug te keren naar het woord dat eraan voorafging om de betekenis van het actuele woord te achterhalen. Het is als het ware een geheugen dat informatie verzamelt en opslaat over wat het systeem tot nu toe heeft berekend.
RNN’s worden vaak geïmplementeerd als Sequence to Sequence-modellen (Seq2seq of reeks naar reeks-modellen) die vaak bij vertaling worden gebruikt en waarbij de uitkomst een andere lengte heeft dan de input. Omdat de meeste gegevens hier zijn gestructureerd in de vorm van een reeks zoals woorden in een zin – of een reeks pixels in een afbeelding –, kan een Seq2seq-model de reeks coderen in een vector met een vaste lengte, de zogenaamde context vector. Deze vector kan daarna weer gedecodeerd worden naar de gewenste uitvoer, bijvoorbeeld een Franse vertaling van een Engelse zin.
Bottleneck is wel de hoeveelheid woorden die wordt onderzocht. De rekensom wordt exponentieel groter naarmate de zinnen langer worden of meer zinnen erbij betrokken zijn. Dat komt vooral omdat de encoder-decoder gebruikmaakt van vectoren met een vaste lengte. Zinnen die langer zijn en meer informatie bevatten dan tijdens de training werden gebruikt, verminderen de prestaties en nauwkeurigheid van het model drastisch.

Het model leest de meest voorkomende volgorde van woorden (sequence) in, verwerkt die stuk voor stuk en reproduceert die zo goed mogelijk als een nieuwe serie van woorden.

Onder de motorkap bestaat het model uit een encoder en decoder, waarbij de encoder de informatie vastlegt in een vector, ‘context’ genaamd. De encoder verwerkt de complete input in één keer voordat hij deze doorstuurt naar de decoder, die de informatie item voor item reproduceert.
Aandacht tot uw dienst
Een oplossing ligt in een encoder-decoder model dat tegelijk kan uitlijnen en vertalen, een concept dat in de Natural Language Processing wordt aangeduid met de term aandacht (attention).
Omdat het model beperkt is, gaat het slim om met zijn rekenkundige vermogen. In plaats van te proberen de volledige invoer te begrijpen, concentreert het zijn aandacht op díe delen waar de meeste informatie is gelokaliseerd. Dit is het uitlijnen. Het doet dit door contextvectoren te gebruiken die naar de meest informatieve delen van de zin verwijzen om de decoder te helpen om zoveel mogelijk betekenis uit de invoervector te halen. Met deze specifieke relevante informatie kan de decoder dan de juiste output genereren, in een vector passend bij die output.
Een voorbeeld: we weten dat Frans en Engels qua structuur en zinsopbouw redelijk op elkaar lijken. Dat geldt niet voor Engels en Japans, waar een zin begint met het onderwerp en eindigt met het werkwoord. Door gebruik te maken van aandacht is het model in staat zelfstandig dit verschil op te merken. Door het gewicht te verschuiven kan het zich dan focussen op de belangrijkste delen van de tekst. Dit levert een dramatische verbetering op in de vertaling. Traditionele coderings-decoderingsmodellen kunnen dit niet en zouden proberen het Japans te begrijpen alsof het een vergelijkbare structuur had als het Engels.
Toch zijn we er niet. Hoewel modellen met attention een grote sprong voorwaarts zijn, worstelen ze nog steeds met lange afhankelijkheden, zoals relaties tussen woorden die meerdere zinnen kunnen omvatten. Gelukkig is ook hier een oplossing voor gekomen: Transformers.

Verschil tussen afhankelijkheid in distributies. De flat distributie krijgt een evenredige aandacht over de gekozen woorden en maakt een duidelijke weging voor omliggende woorden. De peaked distributie heeft een duidelijke voorkeur voor een bepaald woord.
Transformers: aandacht modellen in vermomming
Het blijkt dat aandacht een heel krachtig hulpmiddel is voor Natural Language Processing. Eigenlijk is aandacht alles wat je nodig hebt en kun je toe zonder RNN. Een aangepast model met alleen aandacht blijkt namelijk in staat om grote verbeteringen aan te brengen in de meeste NLP-gerelateerde taken. Dit nieuwe model, transformer genaamd, gebruikt zogenaamde parallelle aandacht-mechanismen om een beter schema te produceren van de tekst dat het codeerde en decodeerde. Het heeft niet alleen lagere trainingskosten maar ook een hogere precisie. Daarmee wordt dit model zeer interessant voor bedrijven en organisaties. Vanuit OCS hebben we het afgelopen jaar een R&D-project gedraaid bij een grote detacheerder waarbij we transformers gebruikten. Dat verliep zeer succesvol.
In het volgende artikel leg ik uit wat het geheim is achter deze transformers en voor welke taken ook jij ze kunt gebruiken. Stay tuned!
Nieuwsgierig naar wat NLP voor jouw organisatie kan doen?
De techniek is ver ontwikkeld en veel onderzoek wordt vrijgegeven. Ookt de enorm gegroeide rekenkracht van gewone computers heeft NLP voor velen binnen bereik gebracht – ook voor organisaties van kleinere omvang. Kijk hier voor een aantal voorbeelden van NLP voor kleinere organisaties. Het enige dat je nodig hebt, is een database met teksten van en over je organisatie of klant. Met onze rekenmodellen kunnen we dan direct aan de slag.
Wil je weten of slimmer omgaan met tekst en taal ook voor jouw organisatie interessant is? Bijvoorbeeld het verbeteren van het contact met je klanten door geautomatiseerde personalisatie? Neem dan gerust vrijblijvend contact met ons op of bel naar +31 40 30 41 330 om eens te sparren. Het zal je verrassen wat er mogelijk is. Wij denken graag met je mee en geven proactief advies. Over mogelijkheden, ontwikkelkosten maar ook over de gevolgen op lange termijn: wat levert het je op aan flexibiliteit en tijdbesparing? Wij zijn een no-nonsense bedrijf: als het simpel kan, houden we het simpel – maar we gaan door als het voor andere partijen te lastig wordt.
Dit stuk is geschreven door Sander Kerdijk, die binnen Open Circle Solutions verantwoordelijk is voor data science-gerelateerde oplossingen. De afgelopen jaren heeft hij voor zowel overheid als de commerciële sector verschillende succesvolle projecten geleid.

e-book
Optimaal plannen
Plannen op maat geeft jouw organisatie een uniek onderscheidend voordeel. Lees hier hoe en waarom.
Meer artikelen

Natural Language Processing 2: automatiseer je teksten
Transformers maken Natural Language Processing tot een technologie die voor veel bedrijven een haalbare en interessante oplossing is. Ben je een organisatie waar veel teksten worden geproduceerd, geanalyseerd en verwerkt? Rapporten, gebruiksaanwijzingen, mails en...

StorePal, inzicht in loyaltyprogramma’s voor retailers
Brand Loyalty verzorgt voor zijn retailklanten de complete merkactivatie van loyaliteitsacties in de winkel. Denk aan de displays voor de promotionele producten, de instore etalage van de producten, de zegels, de posters en de spaarkaarten. Maar hoe effectief zijn die...

Smart Rollator
Een Smart app bouwen voor een Smart rollator, dat is wat wij in samenwerking met Libra Revalidatie & Audiologie hebben gedaan. Genoeg bewegen is voor iedereen van groot belang om gezond en fit te blijven leven. Zeker voor mensen die minder goed ter been zijn, door...
Nieuwsbrief
Meld je nu aan voor Open Circle Stories en krijg een verzameling artikelen, tips, nieuws en verdiepingen in je mailbox.
vragen?
Algemeen: +31 40 304 1330
Afdeling verkoop: +31 40 304 1572
info@opencirclesolutions.nl
Kantoor adres:
Daalakkersweg 16
Kantoor 6
5641 JA Eindhoven

