Natural Language Processing 2: automatiseer je teksten
Transformers maken Natural Language Processing tot een technologie die voor veel bedrijven een haalbare en interessante oplossing is. Ben je een organisatie waar veel teksten worden geproduceerd, geanalyseerd en verwerkt? Rapporten, gebruiksaanwijzingen, mails en reacties van klanten, online testimonials? Dan kun je diverse processen automatiseren met NLP. Het zijn Transformers die dit mogelijk maken. Door hen is deze technologie snel, schaalbaar en veel gemakkelijker in productie te nemen.
Transformers centraal
Zoals al gebleken uit het eerste deel van deze reeks over Natural Language Processing waren de afgelopen twee jaar allesbehalve saai op gebied van natuurlijke taalverwerking, of beter gezegd NLP. Met baanbrekende doorbraken vooral met de introductie van aandacht is een nieuwe generatie NLP-modellen ontstaan.
We eindigden deel 1 met de introductie van zgn. Transformers. Wat maakt hen nou zo bijzonder? Dat zit ’m in drie dingen:
- Zelf-aandacht (self-attention)
- Stacking (stapelen)
- Parallellisering
Ik leg ze hieronder voor je uit.
Zelf-aandacht
We zagen dat ‘aandacht’ (attention) de computer in staat stelt woorden te beoordelen op hun informatiewaarde. Sommige woorden in een zin zijn nu eenmaal belangrijker dan andere. Als je deze correct interpreteert, volgt de rest van de zin meestal vanzelf. Werken met aandacht kan het proces enorm versnellen omdat je je alleen hoeft te concentreren op een paar woorden, in plaats van allemaal.
Een computer kijkt uiteraard niet naar de feitelijke woorden, maar naar een gedigitaliseerde versie daarvan: de zogenaamde vector-representatie. Daarmee krijgt ieder woord een bepaalde score uitgaande van een rekenmodel waarin grote hoeveelheden teksten vooraf zijn geanalyseerd. Aandacht kijkt naar het belang van het woord in de context van de hele zin op basis van die score. Belangrijke woorden zijn vaak: onderwerp (en verwijzingen daarnaar), lijdend voorwerp, werkwoord, bijvoeglijke naamwoorden, enz. Lid- en bijwoorden dragen meestal minder bij aan de betekenis van een zin, dus krijgen een mindere score.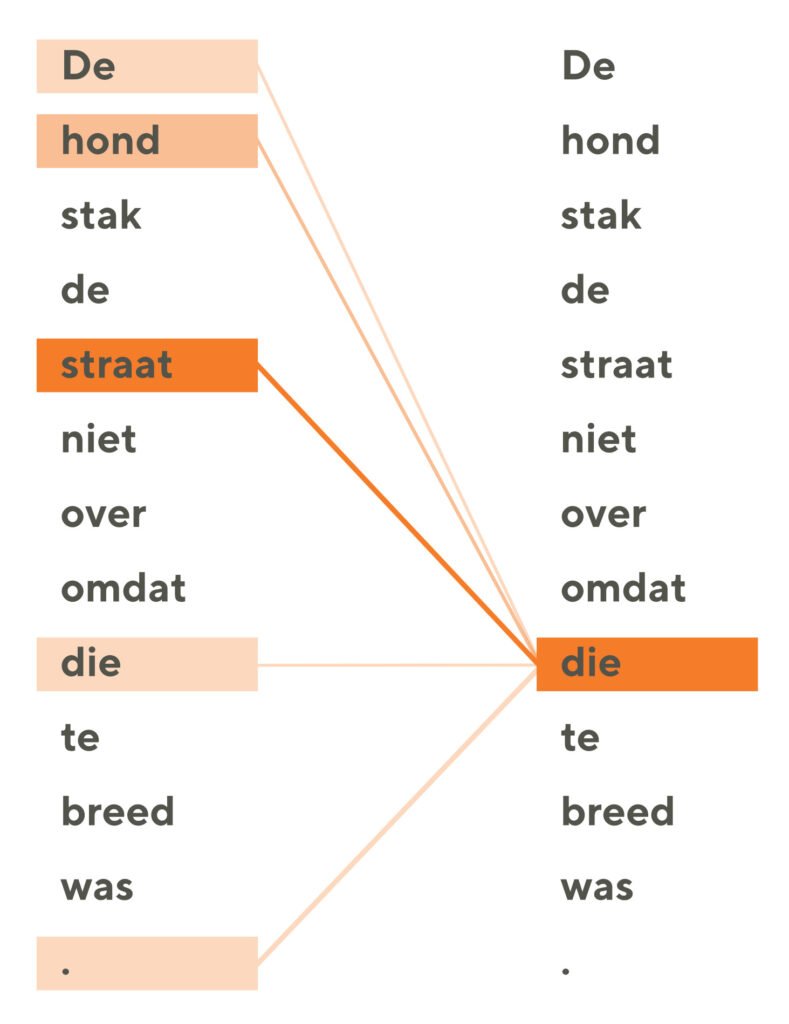
Transformers zijn in staat om met zelf-aandacht interne verwijzingen in een zin te herkennen. Hierbij wordt de zin zelf geanalyseerd en gekeken naar belangrijke en minder belangrijke woorden, en welke woorden eventueel naar elkaar kunnen verwijzen. Zie het voorbeeld hiernaast.
Pas daarna volgt de feitelijke verwerking: een vertaling bijvoorbeeld. Daar wordt aandacht bij gebruikt. Die verwerking gaat een stuk sneller door het voorwerk dat is gedaan met zelf-aandacht.
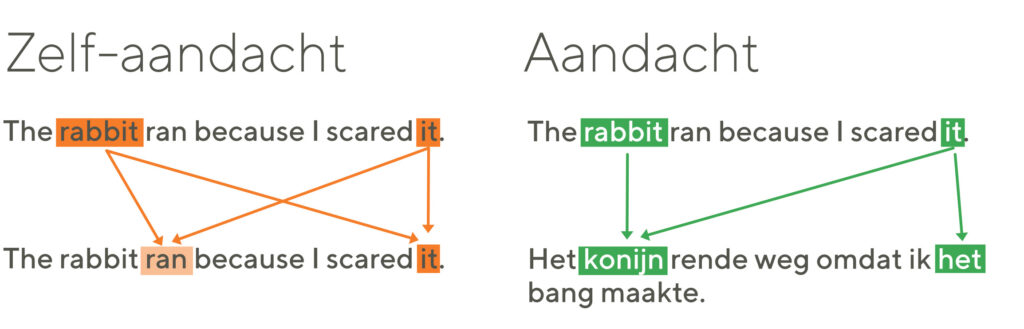
Het verschil tussen zelf-aandacht en aandacht: met zelf-aandacht leert het systeem veel over de opbouw van een zin, onderlinge verwijzingen en het verschil in belang tussen de individuele woorden. Dat is vooral zinvol bij langere, complexe zinnen, waar de klassieke RNN veel problemen mee heeft. Die informatie maakt de complete analyse een stuk sneller.
Stapelen
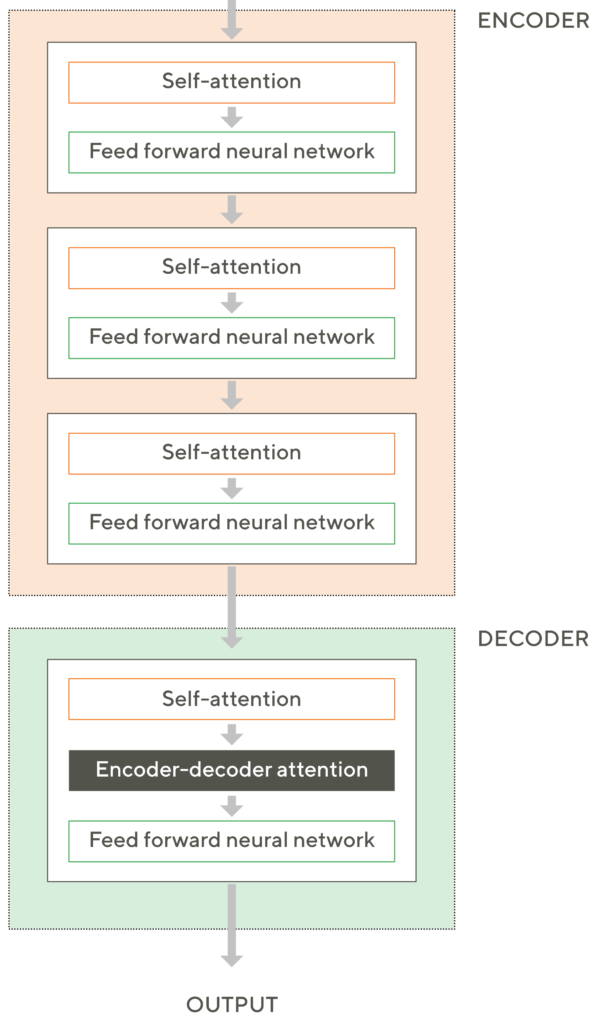 Bij Recurrent Neural Networks worden zinnen vertaald door alle losse woorden afzonderlijk te analyseren, te vertalen en daarna weer aan elkaar te plakken. Transformers zijn in staat om complete zinnen in één keer mee te nemen en te verwerken. De effectiviteit van het systeem wordt veel hoger door zowel de encoders als decoders te stapelen (stacking). Per proces wordt de zin hiermee niet één keer maar meerdere keren geanalyseerd.
Bij Recurrent Neural Networks worden zinnen vertaald door alle losse woorden afzonderlijk te analyseren, te vertalen en daarna weer aan elkaar te plakken. Transformers zijn in staat om complete zinnen in één keer mee te nemen en te verwerken. De effectiviteit van het systeem wordt veel hoger door zowel de encoders als decoders te stapelen (stacking). Per proces wordt de zin hiermee niet één keer maar meerdere keren geanalyseerd.
De encoder zelf bestaat uit een zelf-attentie-component, en een feed forward-NN. Deze encoder wordt dus, zoals gezegd, meerdere keren toegepast. Het resultaat van een bewerking wordt als input meegegeven naar de volgende, zodat het systeem steeds accurater wordt. De decoder maakt ook gebruik van zelf-aandacht én aandacht bij het decoderen.
Door het stapelen kunnen meerdere en complexere eigenschappen van de zin worden meegenomen in de analyse: patronen, samenstellende delen, afhankelijkheden en verwijzingen, semantiek enz. Dat maakt dat het systeem veel accurater is in de analyse.
Parallellisatie
Het belangrijkste voordeel van Transformer-modellen is dat ze niet sequentieel van opbouw zijn: de invoervolgorde maakt niet uit. Hierdoor kunnen ze meerdere afhankelijkheden tussen verschillende woorden in een zin tegelijkertijd berekenen (parallellisering). Dit maakt de berekening van de complete zin dramatisch veel sneller. Zo kunnen transformers worden getraind om grote hoeveelheden tekst razendsnel te analyseren.
Kansberekening en maskeren
Het uiteindelijke resultaat van het NLP-proces (een vertaalde zin, een zoekresultaat of suggestie voor een beter woord of een handeling op basis van een gesproken commando) is uiteindelijk een combinatie van drie elementen:
- de output uit de decoder
- een database van bijvoorbeeld woorden en zinnen, uit te voeren handelingen of beschikbare internet-pagina’s
- én een waarschijnlijkheidsberekening. Als het systeem niet precies weet welk woord er wordt bedoeld op een bepaalde plek, doet het een gok. Dat kan goed uitpakken, of fout. Met training (hulp van een menselijke observator) gaat dit steeds beter, totdat de computer in staat is met grote accuratesse de juiste woordvolgorde en daarmee de betekenis van de tekst te ‘raden’. Daarvoor hoeft de zin niet eens volledig te zijn geanalyseerd. Sommige, minder belangrijke woorden, kunnen worden ‘gemaskeerd’ en leeg gelaten in de uiteindelijke output. De computer kan die later zelfstandig aanvullen en raden op basis van eerdere training.
Het fijne van Transformers is, dat je ze kunt trainen voordat je ze gebruikt voor een specifieke taak. Zo kun je hem gemaskeerde woorden in zinnen laten raden door hem een heel woordenboek of de complete Wikipedia te voeren en laten analyseren. Vroeg of laat, en met veel training, wordt de computer hier beter in dan de mens.
Van Transformers naar BERT
Natuurlijk zijn Transformers niet het eindpunt van deze ontwikkeling. Maar ze zijn wel een heel belangrijke stap, én vertrekpunt voor zeer interessante nieuwe. Zo is veel van de tekst- en spraakherkenningstechnologie van Google gebaseerd op het in 2018 geïntroduceerde BERT (Bidirectional Encoder Representations from Transformers). Met BERT kan Google zinnen afmaken, geautomatiseerd vragen beantwoorden of detecteren of een tekst een positieve, neutrale of juist negatieve lading heeft (sentiment analysis). Dit laatste wordt gebruikt bij het analyseren van klantreviews, reactieformulieren en online beschrijvingen.
Use-cases
- Google: begrijp zoekopdrachten in gewone mensen-taal
De reden van Google voor het ontwikkelen van dit BERT was het verbeteren van de zoekresultaten. BERT-modellen zijn in staat om de volledige context van een woord in overweging te nemen door te kijken naar de woorden die ervoor of erna komen. Dit is vooral handig om de intentie achter de zoekopdrachten te begrijpen. Dit model kan een zoekopdracht in gewone mensen-taal of waar voorzetsels als ‘voor’ of ‘om’ toch belangrijk zijn, correct verwerken. BERT kan ook zoekresultaten wegen op relevantie als volledigheid, in meerdere talen. - Facebook: bestrijding van aanzetten tot online haat en pesten
Nadat Google besloot om de broncode van BERT vrij te geven, heeft Facebook een aangepaste vorm hiervan ontwikkeld: RoBERTa. Dit model is geoptimaliseerd om één van de meest lastige problemen van het internet en sociale netwerken in het bijzonder aan te pakken: inhoudsmoderatie. Door het model vanaf het begin in meerdere talen te laten leren, kon het model een statisch beeld vormen van haatzaaiende uitlatingen en/of pesten, onafhankelijk van de taal. Dit resulteerde in een generieke oplossing waarmee pesten op Facebook wordt tegengegaan. Het platform wist hiermee binnen zes maanden 70% meer schadelijke inhoud weg te filteren – zonder interventie van een menselijke expert. - Visma: automatisch inlezen en verwerken van facturen
Met behulp van het BERT-model heeft Visma een eigen versie getraind. Deze is in staat om digitale facturen in te lezen. Het systeem geeft automatisch suggesties voor hoe een factuur moet worden ingeboekt. Ook laat het je weten als er iets mist op de factuur. Het maakt automatisch een slimme zoekopdracht aan op basis van een vergelijking tussen specifieke kenmerken en vergelijkbare vermeldingen op de factuur. Hierdoor worden klanten en/of projecten automatisch aan elkaar verbonden. Ook worden fouten gecorrigeerd die zijn gemaakt bij het inlezen of het opmaken van de factuur.
NLP ook voor jouw bedrijf?
Recente technologische doorbraken zoals de Transformer-modellen, BERT en zijn varianten worden ontwikkeld en gebruikt door grote spelers zoals Google, Amazon of Microsoft. Dat wekt de indruk dat NLP een soort science fiction is of alleen haalbaar voor dit soort grote organisaties. Maar niets is minder waar.
De techniek is ver ontwikkeld en veel onderzoek wordt vrijgegeven. Ook de enorm gegroeide rekenkracht van gewone computers heeft NLP voor velen binnen bereik gebracht – ook voor organisaties van kleinere omvang. Kijk hier voor een aantal voorbeelden van NLP voor kleinere organisaties. Het enige dat je nodig hebt, is een database met teksten van en over je organisatie of klant. Met onze rekenmodellen kunnen we dan direct aan de slag.
Wil je eens sparren over hoe je de volgende stap kunt zetten in je digitale optimalisatie met NLP? Neem dan gerust vrijblijvend contact met ons op of bel naar +31 40 30 41 330. Het zal je verbazen wat er mogelijk is.
Meer artikelen

Veiligheid en kwetsbaarheden in de cloud – deel 2
Wij vroegen onze collega en cloudexpert Tommy Menheere ons meer te vertellen over veiligheid en de belangrijkste kwetsbaarheden in de cloud. In het eerste deel van deze blogserie vertelde hij ons welke aspecten je in de gaten moet houden om veilig in de cloud te...

Veiligheid en kwetsbaarheden in de cloud – deel 1
Steeds meer organisaties maken gebruik van de cloud. Niet alleen voor applicaties, maar ook voor dataopslag. De cloud maakt organisaties flexibeler, want het maakt niet meer uit waar medewerkers hun werk doen. Via de pc, smartphone of laptop. Op kantoor, onderweg en...

Doordacht migreren met de 6R cloud-migratiestrategie
Wanneer je je IT-infrastructuur van on-premises wilt migreren naar de cloud, kun je dat op veel manieren succesvol doen. Welke je ook kiest: beginnen zonder een solide strategie is niet de beste optie. In dit blog gaan we dieper in op de 6R’s. Dit zijn zes strategieën...
Nieuwsbrief
Meld je nu aan voor Open Circle Stories en krijg een verzameling artikelen, tips, nieuws en verdiepingen in je mailbox.
vragen?
Algemeen: +31 40 304 1330
Afdeling verkoop: +31 40 304 1572
info@opencirclesolutions.nl
Kantoor adres:
Daalakkersweg 16
Kantoor 6
5641 JA Eindhoven

